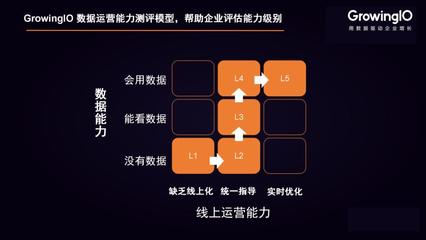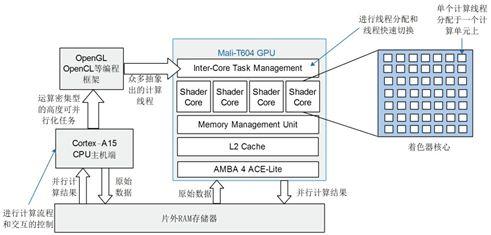
在移動設備和嵌入式系統(tǒng)中,Mali GPU憑借其優(yōu)異的能效比,已成為圖形渲染與通用計算的關鍵組件。將計算密集型的二維浮點矩陣運算(如矩陣乘法、卷積等)遷移至Mali GPU執(zhí)行,能顯著提升性能并降低CPU負載。本文將深入探討Mali GPU的編程特性,并結(jié)合實戰(zhàn)技巧,詳細解析針對二維浮點矩陣運算的并行優(yōu)化策略。
一、Mali GPU核心架構與編程模型特性
Mali GPU通常采用基于瓦片(Tile-Based)的渲染架構,其計算核心由著色器核心(Shader Core)組成。在編程層面,主要支持OpenCL ES(用于通用計算)和Vulkan(兼顧圖形與計算)兩種API。關鍵特性包括:
- 分層內(nèi)存體系:包括私有內(nèi)存(Private Memory,線程獨享)、本地內(nèi)存(Local Memory,工作組內(nèi)共享)和全局內(nèi)存(Global Memory,所有線程可見)。優(yōu)化數(shù)據(jù)在各級內(nèi)存間的移動是性能關鍵。
- SIMD/SIMT執(zhí)行模型:Mali GPU通過單指令多線程(SIMT)方式執(zhí)行,一個線程束(通常是4個線程)同步執(zhí)行相同指令但處理不同數(shù)據(jù)。
- 工作組(Work-Group)調(diào)度:計算任務被劃分為工作組,在著色器核心上調(diào)度執(zhí)行。合理的工作組大小對隱藏訪存延遲至關重要。
二、二維浮點矩陣運算的并行化分解策略
以矩陣乘法C = A × B(假設維度均為N×N)為例,經(jīng)典的優(yōu)化思路是:
- 線程映射:將輸出矩陣C的每個元素(或一個小塊)的計算分配給一個獨立的GPU線程。這樣可生成N×N個并行任務,實現(xiàn)大規(guī)模并行。
- 工作組劃分:將輸出矩陣劃分為若干二維塊(如16×16或32×32),每個塊由一個工作組負責計算。工作組內(nèi)線程通過本地內(nèi)存協(xié)作,高效復用從全局內(nèi)存讀取的A和B矩陣數(shù)據(jù)塊。
- 循環(huán)分塊(Tiling)優(yōu)化:由于單個元素計算需要訪問A的一整行和B的一整列,直接實現(xiàn)會導致大量重復的全局內(nèi)存訪問。優(yōu)化方法是:將計算分解為多個階段,在每個階段,工作組先將A的一個子塊和B的一個子塊從全局內(nèi)存加載到快速的本地內(nèi)存中,然后所有線程基于這些子塊進行部分和累加。這能極大減少昂貴的全局內(nèi)存訪問次數(shù)。
三、針對Mali GPU的關鍵優(yōu)化技巧
- 優(yōu)化內(nèi)存訪問模式:
- 合并訪問(Coalesced Access):確保工作組內(nèi)連續(xù)的線程訪問全局內(nèi)存中連續(xù)(或具有規(guī)則步長)的地址。例如,在讀取矩陣A的塊時,讓線程0讀取A(0,0),線程1讀取A(1,0)... 這樣多次訪問可被合并為一次更寬的內(nèi)存事務,大幅提升帶寬利用率。
- 充分利用本地內(nèi)存:將頻繁訪問的共享數(shù)據(jù)(如矩陣的特定行/列塊)載入本地內(nèi)存。Mali GPU的本地內(nèi)存延遲遠低于全局內(nèi)存,是性能提升的核心。
- 向量化數(shù)據(jù)類型:使用
float4、float8等向量類型進行加載、存儲和計算。這能更有效地利用內(nèi)存帶寬和ALU單元。
- 調(diào)整工作組配置:
- 工作組大小:通常設置為二維,如(16, 16)或(8, 8),并使其總大小(256或64)是GPU硬件線程束大小的整數(shù)倍,且符合OpenCL ES的設備限制。這有助于提高計算資源的占用率。
- 工作項(Work-Item)分工:除了為每個輸出元素分配一個線程的基本模式,還可以讓一個線程負責計算一個小型矩陣塊(如2×2),以減少線程創(chuàng)建開銷并增加指令級并行。
- 指令級優(yōu)化與注意事項:
- 減少寄存器壓力:Mali GPU每個著色器核心的寄存器數(shù)量有限。應避免在內(nèi)核中使用過多私有變量,或通過循環(huán)展開時謹慎控制展開因子,以防寄存器溢出導致性能下降。
- 平衡計算與訪存:通過增加每個線程的計算量(如計算更大的輸出塊)來分攤固定的內(nèi)存訪問開銷,提升計算訪存比。
- 精度選擇:根據(jù)需求,可考慮使用
mediump(中等精度)浮點數(shù)進行計算,這在Mali GPU上通常更快且功耗更低,但需評估精度損失是否可接受。
四、實戰(zhàn)優(yōu)化流程與性能評估
- 基線實現(xiàn):首先實現(xiàn)一個簡單的、每個線程計算一個輸出元素的核函數(shù),作為性能基準。
- 引入循環(huán)分塊與本地內(nèi)存:實現(xiàn)利用本地內(nèi)存緩存數(shù)據(jù)塊的版本,觀察性能提升。
- 優(yōu)化內(nèi)存訪問模式:調(diào)整線程的數(shù)據(jù)讀取順序,確保合并訪問;嘗試使用向量化加載。
- 微調(diào)參數(shù):系統(tǒng)性地調(diào)整工作組大小、循環(huán)分塊大小、每個線程負責的輸出區(qū)域大小等參數(shù),找到針對特定Mali型號和矩陣尺寸的最優(yōu)組合。
- 性能分析工具:利用Arm Mobile Studio中的Streamline或Mali Offline Compiler等工具,分析內(nèi)核的硬件計數(shù)器(如緩存命中率、ALU利用率、內(nèi)存帶寬),定位瓶頸。
在Mali GPU上優(yōu)化二維浮點矩陣運算,精髓在于最大化數(shù)據(jù)復用、最小化全局內(nèi)存訪問、以及保持硬件執(zhí)行單元的高占用率。通過深刻理解其瓦片式架構和內(nèi)存層次,并靈活運用循環(huán)分塊、向量化、工作組優(yōu)化等技巧,開發(fā)者能夠充分釋放Mali GPU的并行計算潛力,為移動端AI推理、圖像處理等應用帶來顯著的性能加速。